
멀티 에이전트 오케스트레이션은 왜 잘 안 되는가?
$5,000어치 토큰을 태우고 배운 것 - 멀티 에이전트 오케스트레이션의 구조적 한계와, 그럼에도 에이전트에게 맡길 수 있는 영역을 판별하는 기준

Claude Code 에이전트 팀, Gastown, Paperclip까지 - 멀티 에이전트 오케스트레이션 시스템을 직접 써보면서 느낀 건, 확실히 효과가 있는 영역은 있다는 것이었습니다. 하지만 효과보다 문제점이 뚜렷했습니다. 이번 기회에 이 문제를 좀 더 깊이 고민해보고, 어떤 영역에서 AI 에이전트에게 더 적극적으로 일을 위임할 수 있는지 판단하기 위한 기준을 세워봤습니다.
들어가며
작년(2025년)부터 새삼 느끼는 건, Claude Code 같은 코딩 에이전트가 단일 요청에 대해서는 이제 거의 잘 작동한다는 것이었습니다. 작업을 구체적으로 정의해주고, 필요한 도구를 쥐어주면 거의 기대한 것 이상의 결과를 가져옵니다. 자연스럽게 다음 질문이 떠올랐습니다. “이걸 좀 더 상위 레벨로 작업을 던지면 AI가 알아서 작업을 쪼개주고 하위 에이전트에게 할당하고 처리한다면 얼마나 큰 레버리지 효과가 날까?”
당연히 저만 이런 생각을 하는 것은 아니겠죠. 이미 이런 시도들은 꽤 많은 층위에서 다양하게 시도되고 있습니다. 그런데 아직 본격적으로 성공한 사례들은 의외로 많지 않습니다. 마침 UC Berkeley의 MAST 연구: Why Do Multi-Agent LLM Systems Fail? 논문에서 대규모로 멀티 에이전트 시스템 구축 실패 사례를 데이터셋으로 만들고 공개했어요. 보면서 “역시 쉽지 않구나...” 싶으면서도, 새롭게 업그레이드 된 LLM 모델의 성능 향상을 체감하게 될 때면, 조만간 놀라운 사례들이 나오지 않을까 그런 상상을 하게 되는데요.
마침 올해 이러한 생각을 극단적으로 밀어붙인 프로젝트들이 눈에 들어왔습니다. 에이전트들을 “도시” 처럼 구성해서 조직하는 Gastown과 “제로 휴먼 컴퍼니”를 표방하는 Paperclip 입니다. 호기심을 못 이기고 모두 직접 써봤습니다. API 토큰 비용을 환산하니 $5,000 정도의 비용을 썼네요. 🫠 효과가 있는 영역들도 분명히 있었지만, 한계점도 꽤 뚜렷했습니다.
이 글에서는 제가 직접 경험한 문제들을 공유하고, 멀티 에이전트 오케스트레이션 시스템에 위임 가능한 영역을 판별하기 위한 기준을 세워보려 합니다.
멀티 에이전트 오케스트레이션이란
그 전에 배경을 짚고 넘어가면 - AI 에이전트 하나가 코드를 잘 짠다면, 여러 에이전트에게 각각 역할을 부여하고(기획, 개발, 테스트, 리뷰), 이들이 자율적으로 협업하게 만들면 하나의 팀처럼 움직이지 않을까? 이게 멀티 에이전트 오케스트레이션의 기본 아이디어입니다. 그리고 이건 실험 수준이 아니고 실제 업계 전반에서 일어나고 있는 흐름입니다.
실제 구현들 - Steve Yegge의 Gastown 은 Claude Code 에이전트들을 “도시” 메타포로 조직하는 시스템이고, Paperclip 은 “제로 휴먼 컴퍼니”를 표방하며 에이전트들을 회사 조직도로 관리합니다. ClawTeam 은 리더 에이전트가 워커들을 동적으로 생성하고, 8개 H100에서 2,430개 이상의 ML 실험을 자동화 하고 있습니다.
플랫폼 인프라 - Anthropic은 Claude Code Agent Teams를 실험적 기능으로 공개했고, OpenAI는 Agents SDK에 에이전트 간 작업 인수인계(핸드오프) 기능을 내장했으며, LangChain은 LangGraph Swarm으로 에이전트 간 동적 제어권 전환을 지원합니다.
프로덕트 레벨 - Cursor는 최근 “Third Era“를 선언하며 자율 클라우드 에이전트가 독립 VM에서 병렬 실행되는 클라우드 에이전트를 전면에 내세우기 시작했습니다. 이슈 트래커 도구를 제공하는 리니어는 최근 Linear Next: ‘이슈 트래킹은 죽었다’라는 글을 공유하며 향후 에이전트-인간 협업 플랫폼의 전환을 선포했어요.
상위 에이전트가 목표를 해석하고 하위 에이전트에게 작업을 위임하며, 결과를 모아 다음 단계를 결정하는 패턴은 AI 에이전트 시대의 핵심 시스템 디자인이 되어가고 있습니다.
참, “멀티 에이전트”라고 하면 LangGraph나 CrewAI 같은 워크플로우 프레임워크를 떠올릴 수도 있는데, 이 글에서 다루는 Gastown·Paperclip 같은 시스템과는 성격이 다릅니다. 워크플로우 프레임워크가 미리 정해진 파이프라인 안에서 여러 에이전트를 실행하는 거라면, 여기서 다루는 시스템은 실행 중에 에이전트를 동적으로 생성하고 분산 관리하며, 말 그대로 자율 조직을 구현하려는 시도입니다. 이 두 가지는 결국 맞닿아 있다고 생각하지만 저는 과감하게 밀어붙인 Gastown 과 Paperclip 을 사용해보면서 문제점들이 더 잘 느껴졌습니다.
써보기 전의 기대, 써본 후의 현실
도시형 오케스트레이션으로 웹앱 개발을 시도하다 : Gastown
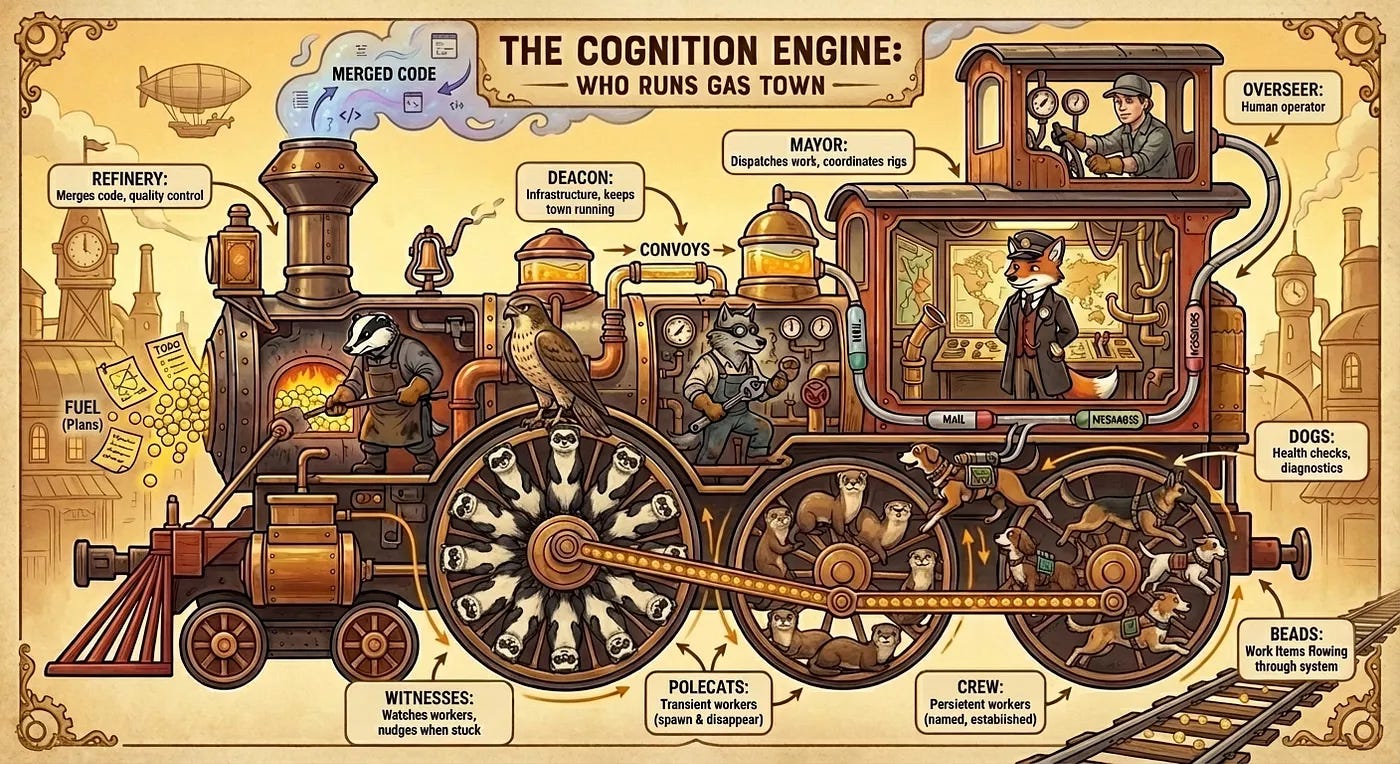
먼저 Gastown입니다. Mayor(시장)가 전체를 관장하고, 최상단에 있는 Human(인간)은 주로 시장에게만 명령을 하달합니다. 프로젝트별 작업장(Rig)이 있고, 워커 에이전트들이 독립적으로 개발하는 구조이고 특정 커뮤니티에서 꽤 열광적인 반응이 있었습니다. 관련 메모리 시스템인 Beads는 출시 5개월 만에 GitHub 스타 2만개 돌파할 정도였습니다. 이 그림만 봐도 이미 이해해야할 상당히 많은 개념과 메타포들이 있는데요. 이러한 부분을 이해해야만 제대로 쓸 수 있다는 게 꽤나 큰 진입 장벽이었지만, 호기심을 못 이기고 웹 애플리케이션 개발 공장을 가동시켜 보았습니다.
결과부터 말하면, 토큰은 단일 에이전트 세션 대비 체감 최소 10배 가까이 소비하면서도 생산성은 오히려 떨어졌습니다.

한 에이전트가 맥락을 이어가며 싸게 끝냈을 작업을, 여러 에이전트가 나눠 갖는 순간 각자가 “지금 상황이 뭐지?”부터 다시 파악해야 하면서 새롭게 세션이 시작되니 비용이 누적됩니다. 토큰이 실제 실행(코드 작성, 문서 생성)보다 상태 전달과 재확인에 훨씬 많이 소모되는 구조입니다. 현 시점에서 이런 오케스트레이션 구조는 비용 대비 완전히 오버스펙이라고 느꼈습니다. 😮💨
워커 에이전트들이 따로 놀면서 merge 충돌도 반복됐고, 오케스트레이션 사이에서 끊어진 맥락을 땜질하는 데 시간을 쏟다 보니 원래 하지 않아도 될 일들만 늘어났습니다.
이건 제 경험만의 문제가 아닙니다. Google DeepMind와 MIT의 공동 연구에서도, 순차적으로 풀어야 하는 작업에서 멀티에이전트가 단일 에이전트보다 성능이 39~70% 떨어진다는 결과가 나왔습니다. 에이전트를 추가하면 무조건 나아질 거라는 직관은, 적어도 지금은 틀렸습니다.
여담: 프로젝트 개발자 Yegge 본인도 초기에 개발 과정을 “serial killer sprees”나 “22-nose Clown Show”로 표현했었고 안정화 되지 않았다고 밝혔습니다. 올해 2월 즈음 많이 개선되었다고 자축하는 글을 보고 뛰어들었는데 꽤 절망하고 그 이후로는 다시 시도하지 않았습니다. 최근 (2026-04-04) Yegge가 “From Clown Show to v1.0“이라는 제목으로 v1.0 출시를 알렸는데, 이 버전은 아직 확인하지 못해서 현재 시점에서 얼마나 개선됐는지는 모릅니다. 한편, v1.0 출시와 함께 Yegge는 Gas Town의 재사용 가능한 인프라를 추출해 Gas City라는 오케스트레이션 빌더 SDK로 전환을 유도하고 있습니다 - 사실상 Gas Town 자체보다 일부 구현 모듈들을 SDK화해서 직접 만들어서 쓸 수 있는 형태의 범용 프레임워크 쪽에 무게를 옮긴 모양새입니다.
회사형 오케스트레이션 : Paperclip
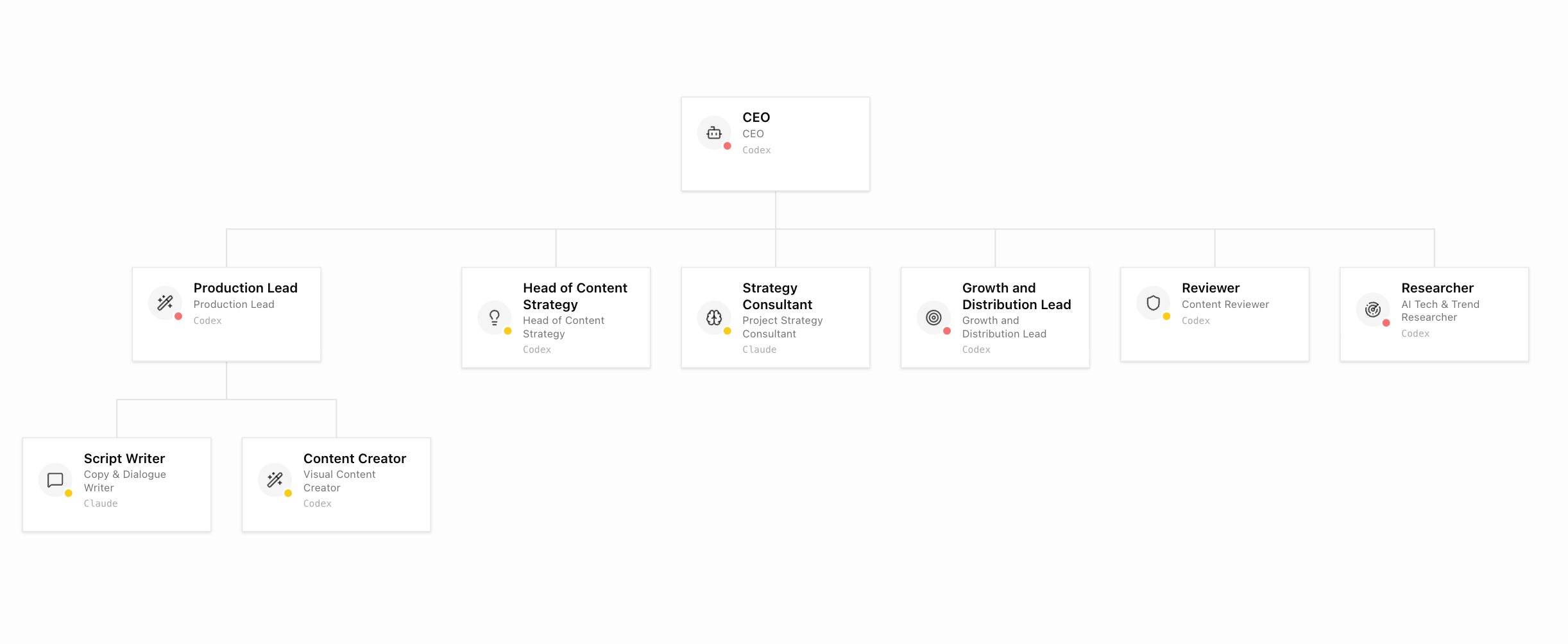
한번의 실패로 포기하긴 아쉬웠던 차, 이번에는 ‘회사’를 메타포로 만든 오픈소스 프로젝트 Paperclip 을 알게 되었습니다. 깃허브 스타는 출시되고 한달만에 4만개를 넘어서고 있었구요. 🤯 설치도 편하고 React 기반 웹앱으로 컨트롤할 수 있는 이슈트래킹 보드 화면까지 모든 구성요소가 잘 구현되어 있고 초기 프로젝트 답지 않게 프로덕트로서의 완성도가 높았습니다. 그래서 다시 한번 시도해보았습니다. 게다가 지난번처럼 기대치를 높게 가져가지 않고, 이런 유형의 시스템에는 어떤 미션이 어울리는지 조금 더 감이 생겼습니다. 순차적으로 풀어야 하는 프로덕트 개발보다는 작은 단위의 업무를 독립적으로 병렬화 시켜서 실행할 수 있는 업무들이 있으면 꽤 순탄하게 알아서 굴러가는 것, 가능할 수 있지 않을까? 그래서 이번에는 프로덕트 개발이 아니라 미디어 에이전시 운영을 맡겼습니다.
가설은 부분적으로 맞았습니다. AI 직원들이 알아서 일하면서 일부 의미있는 결과물들을 만들기도 했습니다. 티켓 기반 워크플로우라 조율이나 개입이 훨씬 쉬웠고, 작업 위임 문제도 상대적으로 덜했습니다. 4단계 목표 체계 (회사 미션 → 프로젝트 목표 → 에이전트 목표 → 개별 작업), 주기적 상태 확인, 에이전트별 예산 관리 같은 장치 덕분에 전체적으로 이 시스템에 대해 확실한 관리 및 제어가 되는 느낌도 좋았습니다.
구체적으로는 에이전트 9개를 구성하고, 주간 콘텐츠 15편 (YouTube Shorts·TikTok·Threads 각 5편) 생산을 목표로 운영했습니다. 하지만 실제 운영 과정에서 문제들은 계속해서 발생했습니다. 개별 에이전트는 각기 다른 이유로 자주 실패하는데 한번 실패하면 쉽게 복구 되지 않았습니다. 결국 문제가 터질때마다 직접 개입해서 튜닝해야 하는데, 운영을 시작하고 일주일 정도는 자동화 시스템에 따른 이득보다는 결국 일을 위한 일이 더 많아지는 역효과가 커졌습니다. 그래도 현재는 많이 나아져서, 제 개인 리소스 투입을 최소화하면서 결과물들이 나오기 시작하고 있습니다. 이것만으로도 상당히 유의미한 성과라고 생각합니다.
하지만 토큰 비용은 분명 원래 같은 아웃풋 대비 최소 5배 이상 소비되는 것 같습니다. 상위 에이전트가 하위 에이전트에게 작업을 넘길 때마다 인수인계 과정에서 캐시가 깨지고, 새로운 세션들이 계속 뜰 수밖에 없기도 하며, 에이전트를 깨우는 트리거가 자주 발생하고, 실행 기록이 쌓이고, 주기적인 상태 확인(heartbeat)까지 별도로 토큰이 소비되면서 돌아갑니다. 조직을 세분화할수록 추론 자체는 분산되는 대신, “지금 상황이 뭐지?”를 파악하는 비용이 매번 반복됩니다. 개별 작업 단위 아웃풋의 품질 역시 단일 에이전트 대비 뛰어나기는 어려운 구조이구요.
3대 구조적 병목
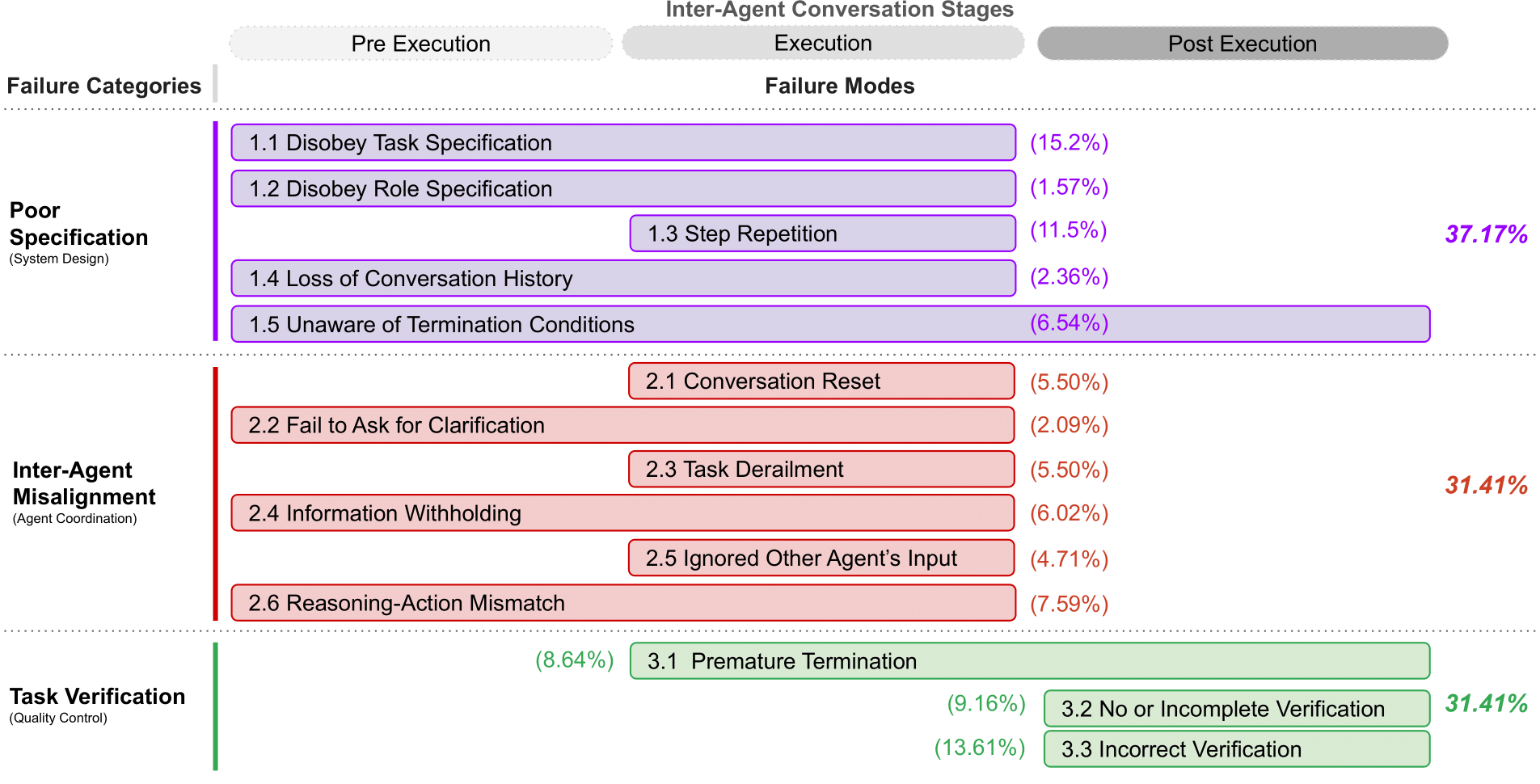
직접 돌려보면서 반복적으로 마주친 문제들을 정리해보니, MAST 연구가 분류한 세 가지 범주와 거의 일치했습니다. 아래는 이 연구의 분류에 제 경험을 대입한 것입니다.
문제 1: Context Collapse (맥락 붕괴) - 에이전트가 전체를 못 봄
전체 실패의 약 41.8%를 차지합니다.
각 에이전트는 자기한테 할당된 작업 설명과 직전 맥락만 봅니다. “왜 이 일을 해야 하는지”를 모르기 때문에, 의도와 다른 방향으로 쉽게 흘러갈 수 있어요.
예를 들어, “사용자 인증 모듈을 구현하라”는 작업을 받은 에이전트는, 이것이 “보안 감사 대비를 위해 기존 세션 토큰 저장 방식을 전면 교체하는 것”인지 “MVP에 간단한 로그인을 붙이는 것”인지 구분하지 못할 수도 있습니다. 맥락이 중간에 소실되면서 최종 작업을 맡게된 에이전트가 가장 그럴듯한 방향을 잘못 예상하기도 합니다.
그리고 여기서 치명적인 연쇄 반응이 일어납니다. 에이전트 하나가 초반에 잘못된 전제를 세우면, 그것이 맥락에 고착되어 후속 에이전트들이 틀린 기반 위에서 작업을 이어갑니다. DeepMind/MIT 연구에 따르면 체계 없이 에이전트를 묶어놓으면 오류가 최대 17.2배 증폭됩니다. 중앙에서 조율하는 구조로 바꾸면 약 4.4배로 억제되지만, 그래도 단일 에이전트보다는 높습니다.
Paperclip이 이 문제를 정면으로 겨냥한 것이 “Goal Alignment(목표 정렬)” 모든 작업이 회사 미션까지 거슬러 올라갈 수 있어야 한다는 원칙인데, 이것이 실제로 에이전트의 맥락에 얼마나 유의미하게 주입되는지는 미지수입니다. Goal 설정과 최종 작업 간에 간극이 너무 벌어지게 되면 효과가 사라진다고 느껴졌습니다.
현실적 해결 방향:
각 작업에 “왜 이 일을 해야 하는지”까지 명시적으로 포함시키기
역설적이지만, 에이전트 수를 줄이고 각자의 담당 범위를 넓히는 것이 나을 때가 많음. DeepMind 연구에서도 에이전트 4개를 넘으면 조율 이득이 더 이상 늘지 않는 것으로 나타남
단일 오케스트레이터(총괄 에이전트)가 전체 목표를 끝까지 유지하는 구조가, 다단계 위임보다 실전에서 강건함
문제 2: Ghost Delegation (유령 위임) - 인수인계가 끊김
전체 실패의 약 36.9%를 차지합니다.
실제로 돌려보면 이런 일이 자주 반복됩니다:
에이전트 A가 DONE → 순간적으로 트리거 이벤트 어떤 식으로든 끊김 (다양한 이유가 존재함) -> 위임되어야할 작업은 무한 대기
Task “In Review” 상태 → Review 할당이 잘못되어 리뷰 진행 안되고 무한 대기
Parent task가 닫힘 → subtask들은 여전히 미완료 상태로 방치
인간 조직에서도 커뮤니케이션 미스는 흔합니다. 하지만 사람은 “그거 어떻게 됐지?”라는 생각을 누군가 하게 되면 자연스럽게 팔로우업이 다시 시작됩니다. 에이전트에는 이런 복구 로직이 완벽하지 않습니다. 이를 위한 대응 프로세스들은 여러 레이어로 돌아가고 있지만 모든 문제에 복구 처리를 기대하긴 어려웠습니다.
특히 git worktree(독립 작업 공간) 기반으로 에이전트들이 각자 작업하는 구조에서도 이 문제가 자주 발생합니다. 각자 작업하다가 합치는(merge) 시점에서 충돌이 나면서 완료처리되었지만 결과는 없는 경우도 있었습니다.
현실적 해결 방향:
모든 완료 보고에 증거를 강제 - 실제 결과물이나 검증 결과 없이는 완료로 인정하지 않음
주기적 상태 확인 + 시간 초과 시 강제 재할당 (빈번하게 하면 토큰 비용 상당히 추가됨)
작업 인수인계 지점마다 명시적 체크포인트 삽입
문제 3: Verification Error (검증 오류) - 실패했거나 수준 미달 패스
전체 실패의 약 21.3%를 차지합니다.
LLM은 쉽게 “그럴듯한 응답”에 대해 스스로 완료했다고 처리합니다. 자기가 쓴 답안을 자기가 채점하는 구조이니 이는 당연하다고 볼 수 도 있습니다. 그래서 검증 프로세스를 별도로 둡니다.
가장 검증된 해결 패턴은 실행-검증-판정(Executor-Validator-Critic) 3단 구조입니다:
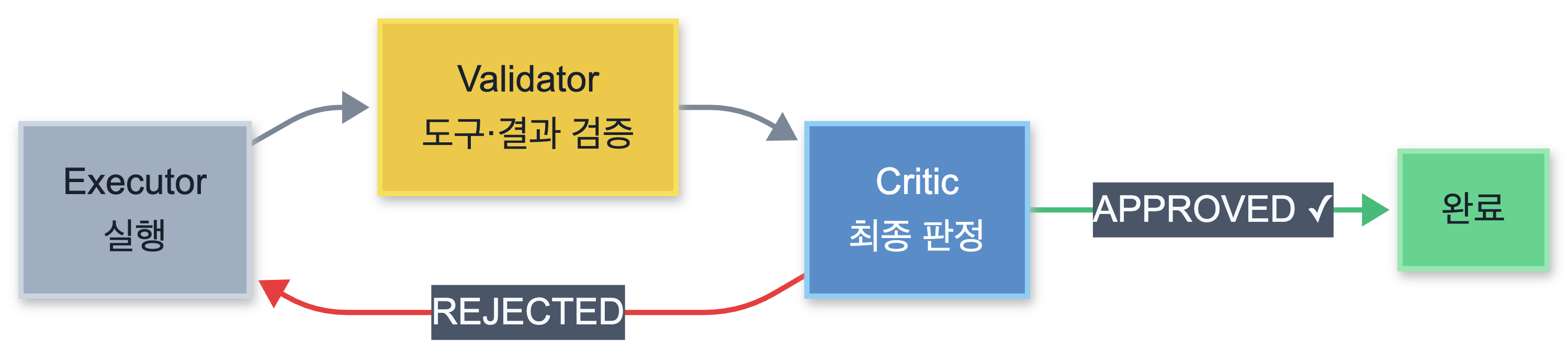
같은 모델, 같은 도구를 써도 역할 분리만으로 조용한 환각(잘못된 결과를 맞다고 믿는 현상)이 상당히 줄어듭니다. 다만 검증 단계가 추가될수록 토큰 비용이 배로 늘고 속도가 느려지는 트레이드오프도 있습니다. 그리고 무엇보다 모든 작업에 정량적인 결과 검증은 어렵습니다. 그래서 이런 경우를 위해 별도 QA 전용 에이전트를 두기도 하는데 이 역시 완벽한 대응책이 되기는 어려웠습니다.
이런 배경에서 관측 가능성(Observability) - 에이전트가 무엇을 하고 있는지, 어디서 막혔는지를 사후적으로라도 투명하게 볼 수 있는 능력 - 이 점점 중요해지고 있습니다.
그렇다면 어떤 구조가 맞는가
에이전트 수가 아니라 오케스트레이터 설계가 핵심이다
맥락 붕괴의 근본 원인은 목표 변질(Goal Drift) - 목표가 위임 단계를 거치면서 원래 의도에서 벗어나는 현상입니다. 이를 구조적으로 방지하려면, 총괄 에이전트 하나가 전체 목표를 끝까지 유지하면서 작업을 점진적으로 구체화하는 구조가 필요합니다.
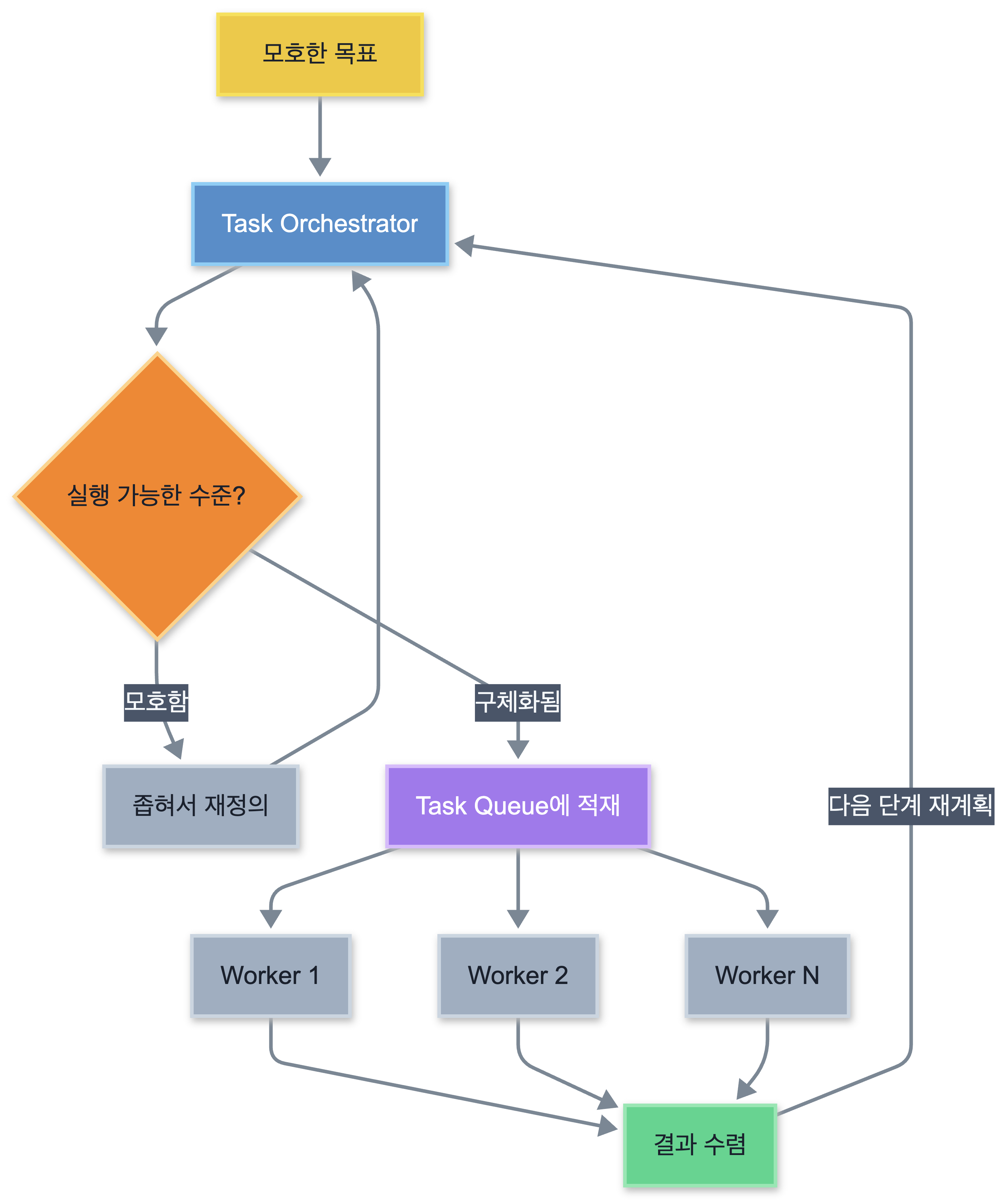
이 패턴은 여러 이름으로 불리지만(Orchestrator-Worker, Plan-and-Act 등), 핵심은 같습니다: 총괄 에이전트가 전체 목표를 계속 보유한 채 재계획할 수 있어야 합니다. AgentOrchestra가 이 구조로 GAIA 벤치마크에서 89.04%라는 높은 성능을 달성한 것은, 이 방식이 잘 설계되었을 때의 가능성을 보여줍니다.
한 가지 강조할 점은 멀티에이전트가 단일 에이전트보다 항상 우월하지 않다는 것입니다. 같은 도구와 정보 접근 권한이 주어졌을 때, 단일 에이전트가 상당수 작업에서 멀티에이전트를 따라잡거나 능가합니다. 멀티에이전트가 역전하는 건 단일 에이전트의 맥락 창으로 감당하기 어려운 복잡한 작업, 병렬 실행이 필요한 경우, 교차 검증이 필요한 경우뿐이었습니다.
진짜 스웜은 대화가 아니라 공유 환경이다
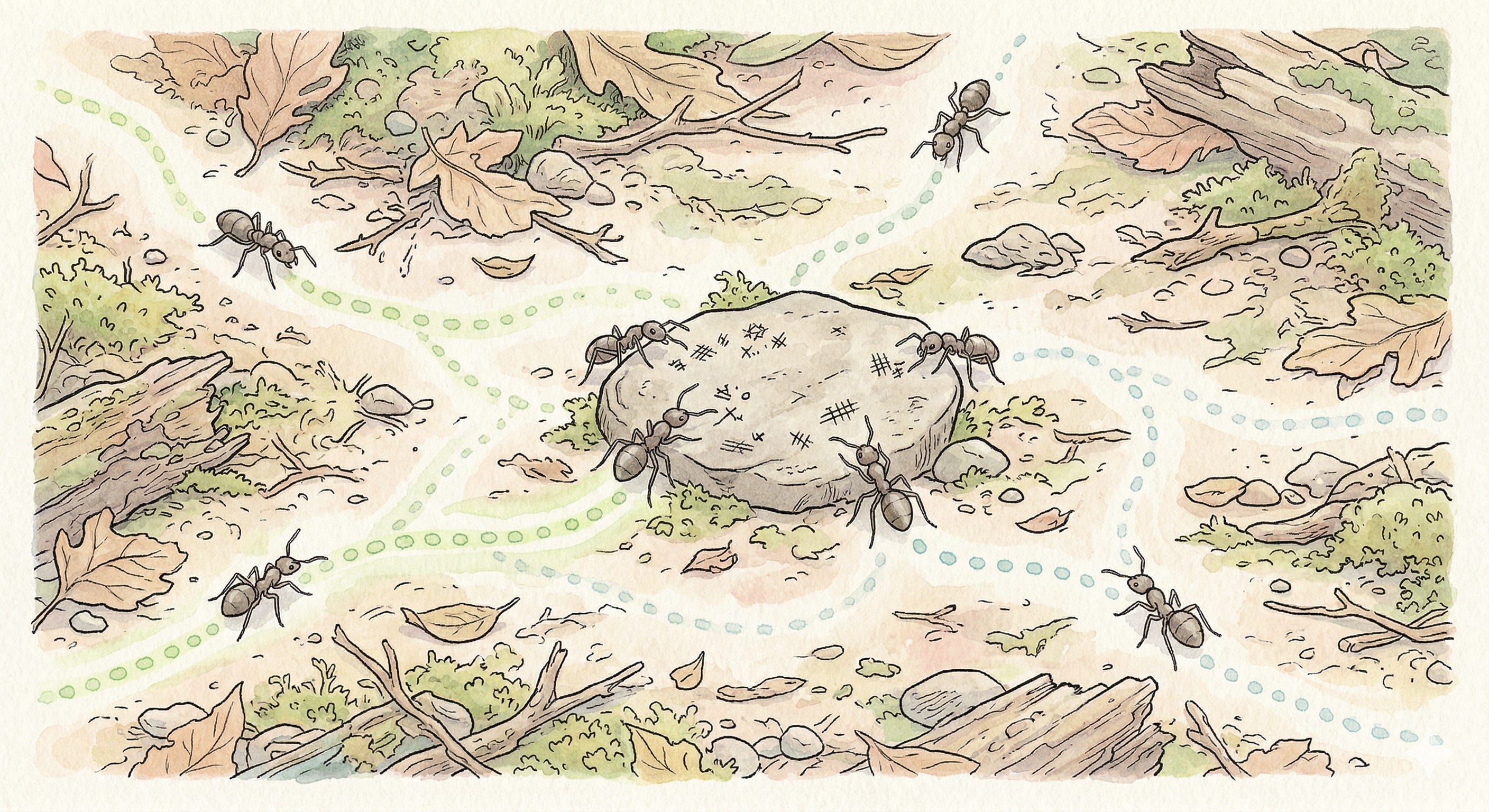
멀티 에이전트 시스템 (MAS) 구축에 있어 에이전트 간 직접 통신(A2A)이 중요하게 언급되지만, 사실 진짜 스웜(Swarm) 지능의 핵심은 오히려 직접 통신이 없다는 데 있습니다. 개미는 다른 개미에게 말을 걸지 않습니다. 페로몬이라는 공유 환경을 읽고 씁니다.
이것은 일종의 블랙보드 패턴(Blackboard Pattern)입니다. 이슈 트래커, Git, 메시지 큐 같은 도구들이 보통 이 역할을 합니다. 에이전트끼리 직접 메시지를 주고받게 만들면, 오히려 “서로를 어떻게 찾을 것인가”, “전체 상태를 누가 관리할 것인가” 같은 분산 시스템의 고전적인 문제가 고스란히 재현됩니다.
실제 경험에서도 티켓과 큐 기반 워크플로우가 에이전트 간 자유 소통 구조보다 안정적이었습니다.
사실 이미 쓰고 있는 도구 안에 답이 있다
총괄-워커 패턴은 이미 우리가 자주 쓰고있는 도구들에 대부분 도입되어 있는데요. Claude Code의 서브에이전트 구조가 대표적입니다. 상위 에이전트가 전체 목표를 유지한 채 작은 작업을 서브에이전트에 위임하고, 결과를 모아서 다음 단계를 다시 계획합니다. 최근에는 여기서 한 걸음 더 나아가 Agent Teams - 리더가 팀원들을 생성하고, 공유 작업 리스트로 조율하며, 에이전트 간 직접 메시징을 지원하는 기능 - 이 실험적으로 공개되었습니다. Cursor 역시 클라우드 에이전트를 독립 VM에서 병렬 실행하는 구조를 쓰고 있습니다.
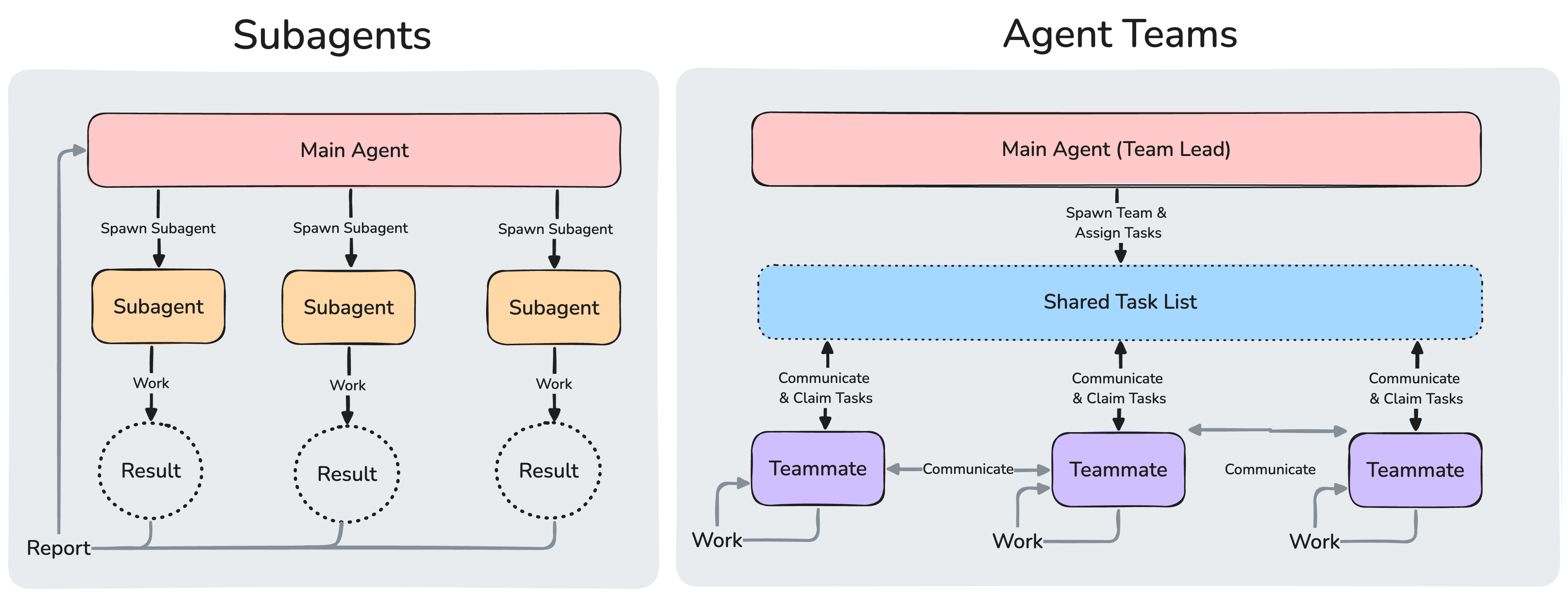
다만 이 도구들은 블랙보드 패턴 - 세션 간 상태 유지, 장기 프로젝트의 연속성, 조직 수준의 관리 체계 - 쪽이 아직 약한 고리입니다. Gastown은 사실 그 자체보다 이 부분만 별도의 Beads 프로젝트로 존재하고 해당 프로젝트만 선호하는 사용자도 많은 편입니다. (저를 포함 😅) Paperclip 역시 시스템 내에 Linear와 유사한 이슈트래커가 완전히 통합되어 있고, 이 부분 덕분에 시스템이 원활하게 돌아갑니다.
하지만 솔직히 말하면, 하나의 작업 안에서 기대할 수 있는 결과물 품질 측면에서 이런 Gastown 혹은 Paperclip 과 같은 오케스트레이션 시스템이 Claude Code의 서브에이전트보다 나을 가능성은 낮다고 봅니다. 상위 에이전트가 전체 맥락을 유지한 채 위임하는 것과, 깨우기 → 맥락 재수집 → 위임을 거치는 것은 효율 차이가 분명합니다. 오케스트레이션 시스템의 진짜 가치는 “단일 작업의 품질”이 아니라 “여러 작업을 장기간 자율적으로 조율하는 것”에 있습니다. 그러므로 그 장기 조율 자체가 아직 안정적이지 않은 경우 이 시스템을 이용할 가치는 매우 떨어지게 됩니다.
도메인별로 깊게, 영역 간에는 느슨하게
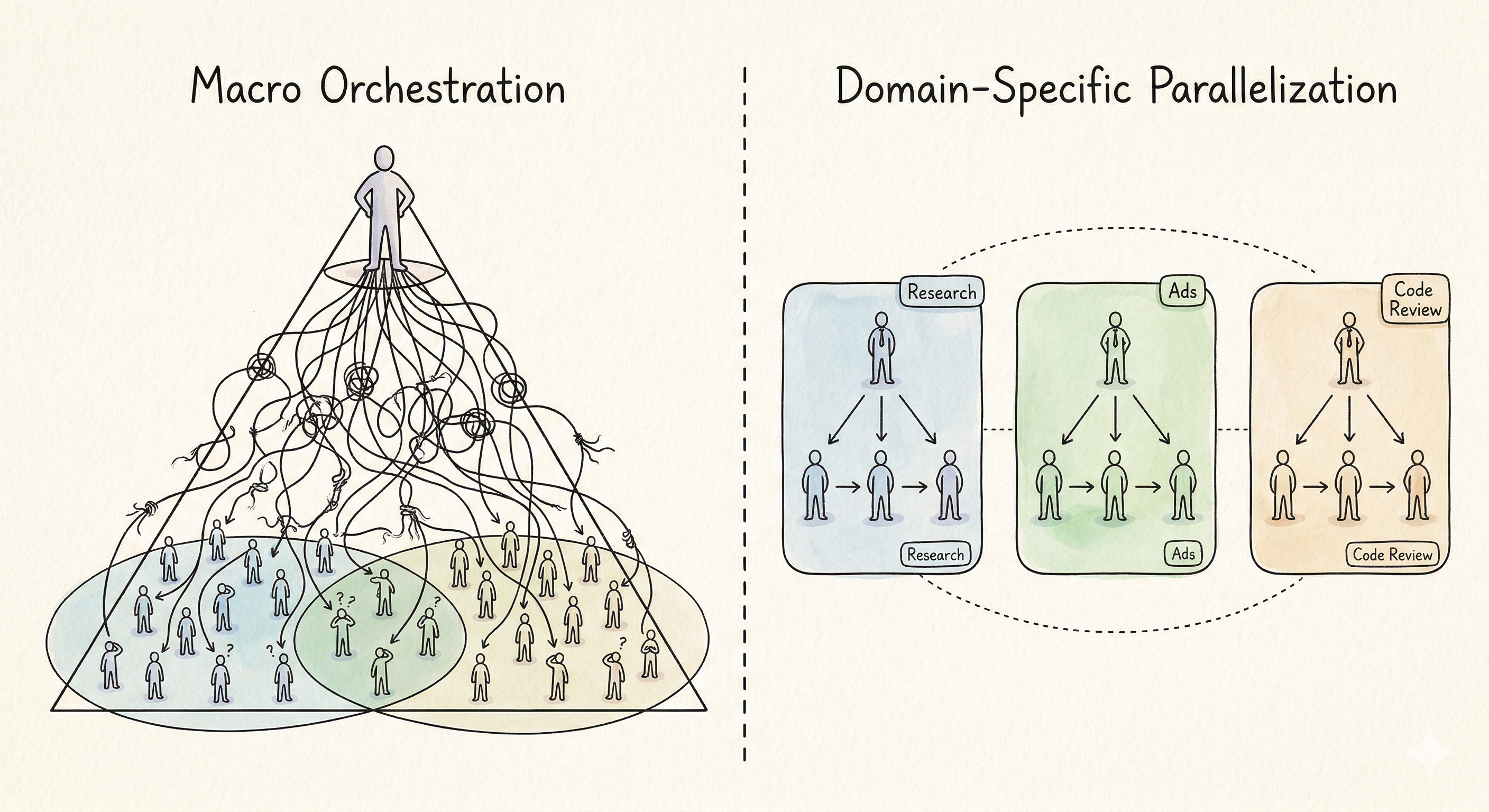
Gastown·Paperclip 같은 시스템이 여러 도메인을 하나의 거시적 오케스트레이션으로 묶으려 했다면, 반대 방향의 접근이라고 볼 수 있는 하나의 기능적 도메인 안에서 에이전트 루프를 깊게 병렬화하는 방향은 이미 이전부터 상당히 진행되고 있었습니다.
대표적인 사례가 Anthropic의 멀티에이전트 리서치 시스템입니다. 리드 에이전트가 쿼리를 분석하고 전략을 세우면, 서브에이전트들이 각자 독립 컨텍스트 윈도우에서 다른 측면을 동시에 탐색합니다. 결과적으로 멀티에이전트 Claude Opus 4(서브에이전트는 Sonnet 4)가 단일 에이전트 대비 90.2% 성능 향상을 보였고, 복잡한 쿼리에서 병렬 도구 호출이 리서치 시간을 최대 90% 단축했습니다.
리서치가 멀티에이전트의 첫 번째 성공 사례가 된 건 우연이 아닙니다. 오류 비용이 낮고, 검증이 쉽고, 암묵지에 의존하지 않고, 각 서브에이전트가 독립적으로 작업할 수 있고, 피드백이 즉각적입니다 - 앞서 분석한 세 가지 병목이 발생할 조건이 구조적으로 거의 없는 겁니다. 토큰은 단일 에이전트 대비 약 15배 소모되지만, 그 토큰이 조율이 아니라 실제 탐색에 비례해서 쓰인다는 점이 Gastown에서의 경험과는 크게 다릅니다.
이 패턴은 리서치에 국한되지 않았습니다. Exa도 비슷한 구조의 딥 리서치 에이전트를 구축했고, Spotify는 광고 미디어 플래닝이라는 전혀 다른 도메인에서 같은 원리를 프로덕션에 적용했습니다. Spotify의 Ads AI는 라우터 에이전트가 요청을 분석하고, 목표·예산·오디언스·스케줄을 각각 담당하는 에이전트들이 병렬로 실행되며, 미디어 플래너 에이전트가 결과를 모으는 구조입니다 - 기존 15~30분 걸리던 미디어 플래닝을 3~5초로 단축했습니다. 핵심은 기존 광고 서비스를 에이전트의 도구로 감싸서(wrapping) 쓴다는 점으로, 새로운 시스템을 처음부터 만드는 대신 기존 인프라 위에 에이전트 레이어를 얹은 것입니다.
시사하는 방향은 같습니다. 거시적인 “자율 조직”을 한번에 구축하기보다, 각 도메인 안에서 에이전트에게 적극적으로 위임하는 것. 리서치, 광고 플래닝처럼 병렬화가 자연스러운 영역부터 시작해서, 코드 리뷰, 테스트 생성, 데이터 분석 같은 영역으로 점진적으로 확장하는 흐름. 각 영역이 명확한 범위 안에서 깊게 병렬 실행되되, 영역 간 조율은 최소화하는 구조입니다.
앞서 여담으로 언급한 Gas Town → Gas City SDK 전환도 결국 같은 방향을 가리킵니다. 하나의 거대한 “도시” 오케스트레이션에서, 도메인별로 조합 가능한 블록으로 분해하는 것 역시 자연스럽게 그러한 방향으로 구체화된 용도를 찾고 있다고 느껴집니다.
어떤 문제가 먼저 풀릴까
세 가지 문제의 해결 전망을 정리하면:
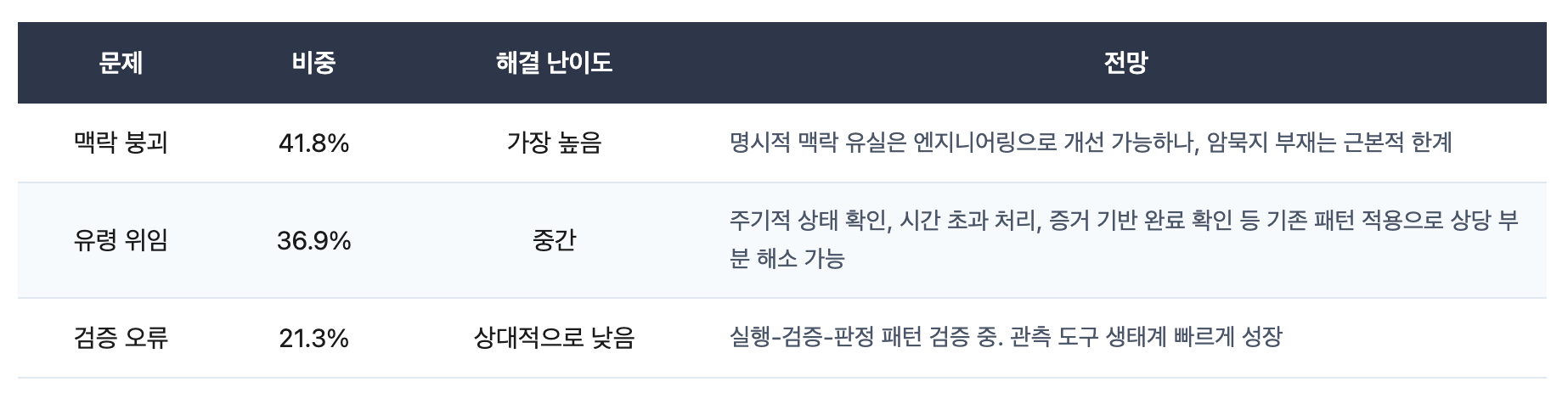
결국 맥락 붕괴가 마지막까지 남는 문제입니다. 그런데 이 문제를 더 깊이 들여다보면 두 개의 층위가 보입니다.
첫 번째 층위는 명시적 맥락의 유실입니다. 목표가 전달되지 않거나, 이전 에이전트의 결정 근거가 소실되는 문제. 이건 엔지니어링 혹은 초기 업무 지시 단계에서 상당 부분 해결이 가능할 수 있습니다.
두 번째 층위는 암묵지의 부재입니다. 함께 일하면서 자연스럽게 체득하는, 말로 다 표현하기 어려운 맥락 - “이 코드베이스에서 왜 이런 패턴을 쓰는지”, “이 고객이 왜 민감한 반응을 보이는지”, “이 팀에서 PR을 올릴 때 암묵적으로 기대하는 수준은 무엇인지”와 같은 것. 인간 팀원이었다면 일하면서 이걸 자연스럽게 흡수하지만, LLM 에이전트에게 이런 학습은 현재 매우 제한적입니다. 세션이 끝나면 경험이 사라지고, 다음 세션은 사전에 정의된 지식만으로 시작합니다.
이것이 맥락 붕괴를 단순 엔지니어링 문제가 아닌 근본적인 한계로 만드는 이유입니다. 명시적 맥락은 전달할 수 있지만, 암묵지는 그 의미대로 문서로 전부 옮기는 것이 어렵기 때문입니다.
에이전트에게 얼마나 맡길 것인가
메타포 자체가 틀렸을 수 있다
이러한 경험 속에서 결국 가장 먼저 의문이 들게 되었던 부분은 “도시”나 “회사”라는 메타포 자체입니다. 에이전트들을 도시 시민이나 회사 직원으로 조직하겠다는 발상은 매력적이고 직관적입니다. 하지만 분명히 AI는 자율의지가 없기에 이러한 메타포를 이용한다고 갑자기 자율적으로 작동하는 시스템이 될 수는 없습니다.
인간 조직 구성원에게는 지속적 기억, 평판, 내적 동기가 있습니다. 팀장이라면 팀원을 마이크로 매니징하기 보다는 명확한 목표를 제시하고 팀원이 자율성에 따라 합리적으로 최선의 행동을 할 수 있도록 유도할 수 있습니다. 팀원은 스스로 성장하고자 하고, 동료의 신뢰를 잃고 싶지 않으며 자기 커리어를 위해 성과를 유지합니다. AI 에게는 이 셋 중 아무것도 없습니다. 그렇기에 에이전트들에게는 마이크로 매니징 (구체적인 지시)이 훨씬 효율적입니다.
그래서 다단계 계층 구조 (Director → Manager → Worker)는 인간 조직에서는 정보 필터링과 권한 위임의 효율을 높여주지만, 에이전트 시스템에서는 목표 변질의 기회만 늘리고 조율 비용을 불필요하게 증가시킵니다. 그래서 에이전트 시스템에서는 계층을 깊이 쌓을 이유가 없습니다. 총괄 에이전트가 전체 목표를 유지한 채 수평적으로 위임하는 구조가, 적어도 현재 시점에서는 훨씬 강건합니다.
수렴점은 어디인가
현실적으로 멀티 에이전트 시스템의 미래는 하나의 극단이 아니라 각 영역별로 조금씩 다른 스펙트럼 위의 수렴이라고 봅니다.
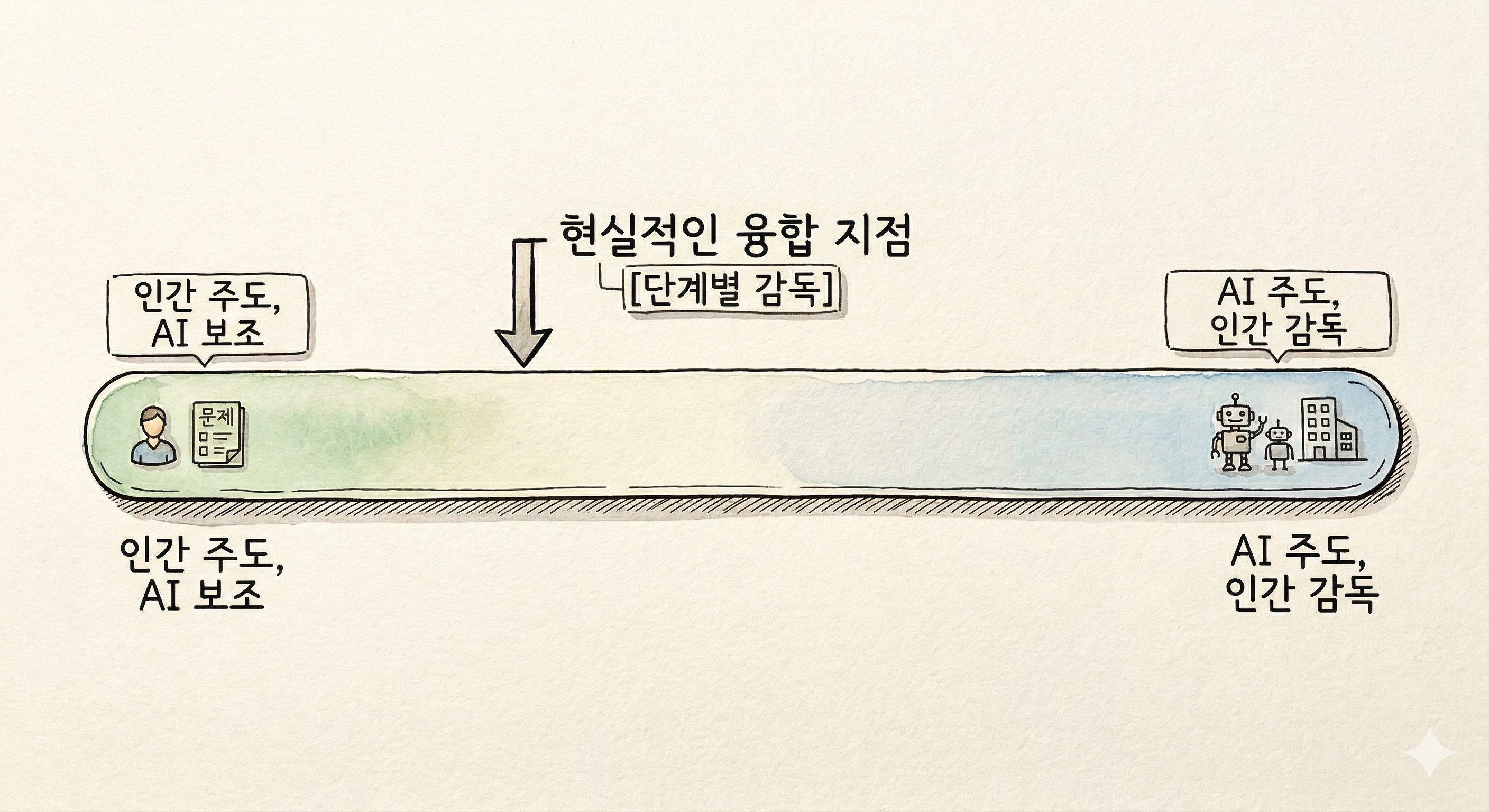
맥락 붕괴의 근본적 문제 - 암묵지 부재가 각 영역별로 그 정도가 다를 수밖에 없지만 다수의 업무가 암묵지가 존재하고 있고, 위임 문제와 검증 문제도 현실적으로 완벽히 풀리지 않는 경우가 많기에 수렴점은 현재로서는 좌측(인간 주도)에 가깝게 형성될 가능성이 높다고 생각됩니다. 점차 많은 영역이 조금씩 우측으로 이동하겠지만 갑자기 우측 끝으로 모든 것이 전환되는 시나리오는 모든 영역별 문제가 풀리는 속도 차이가 존재해서 어려울 것으로 생각됩니다.
그렇다면, 각 도메인 혹은 문제별로 에이전트에게 위임이 수월한 부분들은 어떤 기준으로 판단할 수 있을까요?
다섯 가지 판별 기준: 에이전트에게 얼마나 맡길 것인가
직접 운영하면서 체감한 실패 패턴들과, 앞서 분석한 세 가지 구조적 병목을 역으로 뒤집으면 다섯 개의 판별 기준이 나옵니다.
1. 오류 비용 (Error Cost) - 틀렸을 때 되돌리는 데 드는 비용
“사고 나면 얼마나 아픈가”입니다.
🟢 에이전트 적합: SEO 글 초안, 내부 슬랙 요약, 테스트 데이터 생성
🔴 인간 주도: 고객 대면 커뮤니케이션, 법률 계약, 프로덕션 DB 마이그레이션
2. 검증 용이성 (Verifiability) - 결과가 맞는지 빠르게 판별 가능한가
실행-검증-판정 패턴이 작동하려면 이 부분이 전제 조건입니다.
🟢 에이전트 적합: 테스트 통과 여부, 빌드 성공, diff 리뷰 가능한 코드 변경
🔴 인간 주도: “이 톤이 브랜드에 맞는가”, “이 UX 흐름이 직관적인가”
3. 암묵지 의존도 (Tacit Knowledge Dependency) - 문서화하기 어려운, 경험을 통해서만 전달되는 지식에 얼마나 의존하는가
🟢 에이전트 적합: 명세서가 존재하는 버그 수정, API 연동, 정형화된 보고서
🔴 인간 주도: 팀 문화를 반영한 의사결정, 이해관계자 간 정치적 판단
4. 컨텍스트 범위 (Context Scope) - 단일 세션의 컨텍스트 윈도우로 작업에 필요한 정보를 충분히 담을 수 있는가
🟢 에이전트 적합: 단일 파일/모듈 범위, 명확한 입출력 경계
🟡 하이브리드: 여러 서비스에 걸치지만 API 계약이 명확한 경우
🔴 인간 주도: 코드베이스 전체의 아키텍처 결정, 크로스-팀 의존성
5. 피드백 루프 길이 (Feedback Loop Length) - 결과를 확인하고 방향을 수정하기까지 걸리는 시간
🟢 에이전트 적합: 코드 작성 → 테스트 실행 → 즉시 확인 (초~분 단위)
🟡 하이브리드: 디자인 → 프로토타입 → 유저 반응 (시간~일 단위)
🔴 인간 주도: 전략 수립 → 실행 → 분기별 성과 확인 (주~월 단위)
통합 스코어링
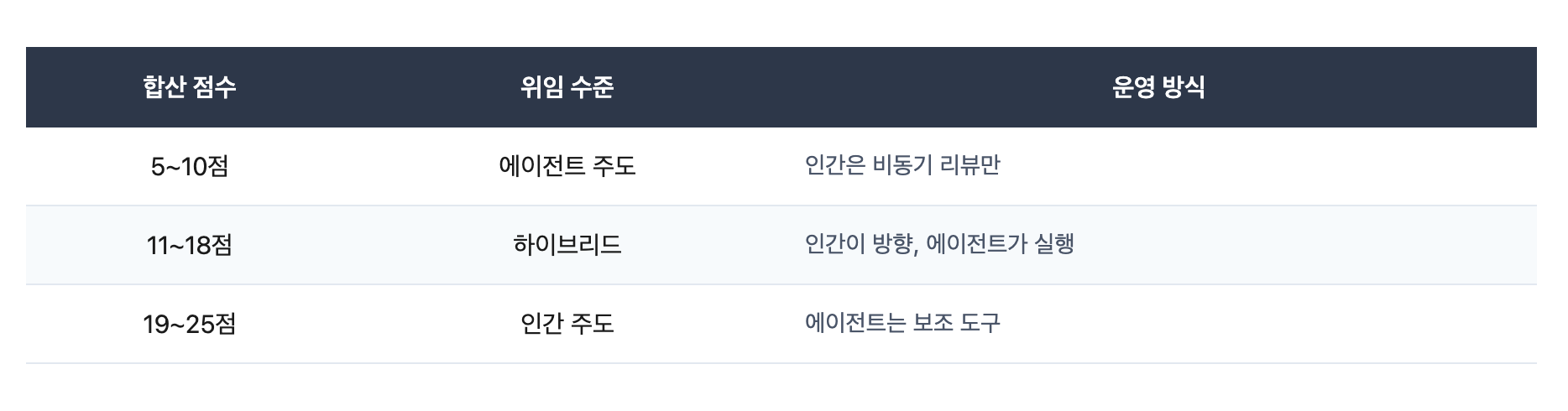
각 변수를 1점(에이전트 유리)~5점(인간 유리)으로 채점하면, 합산 점수로 작업별 위임 수준을 판별할 수 있습니다.
앞서 다룬 사례들과 다양한 도메인의 업무를 이 기준으로 채점해보면, 패턴이 보이기 시작합니다.
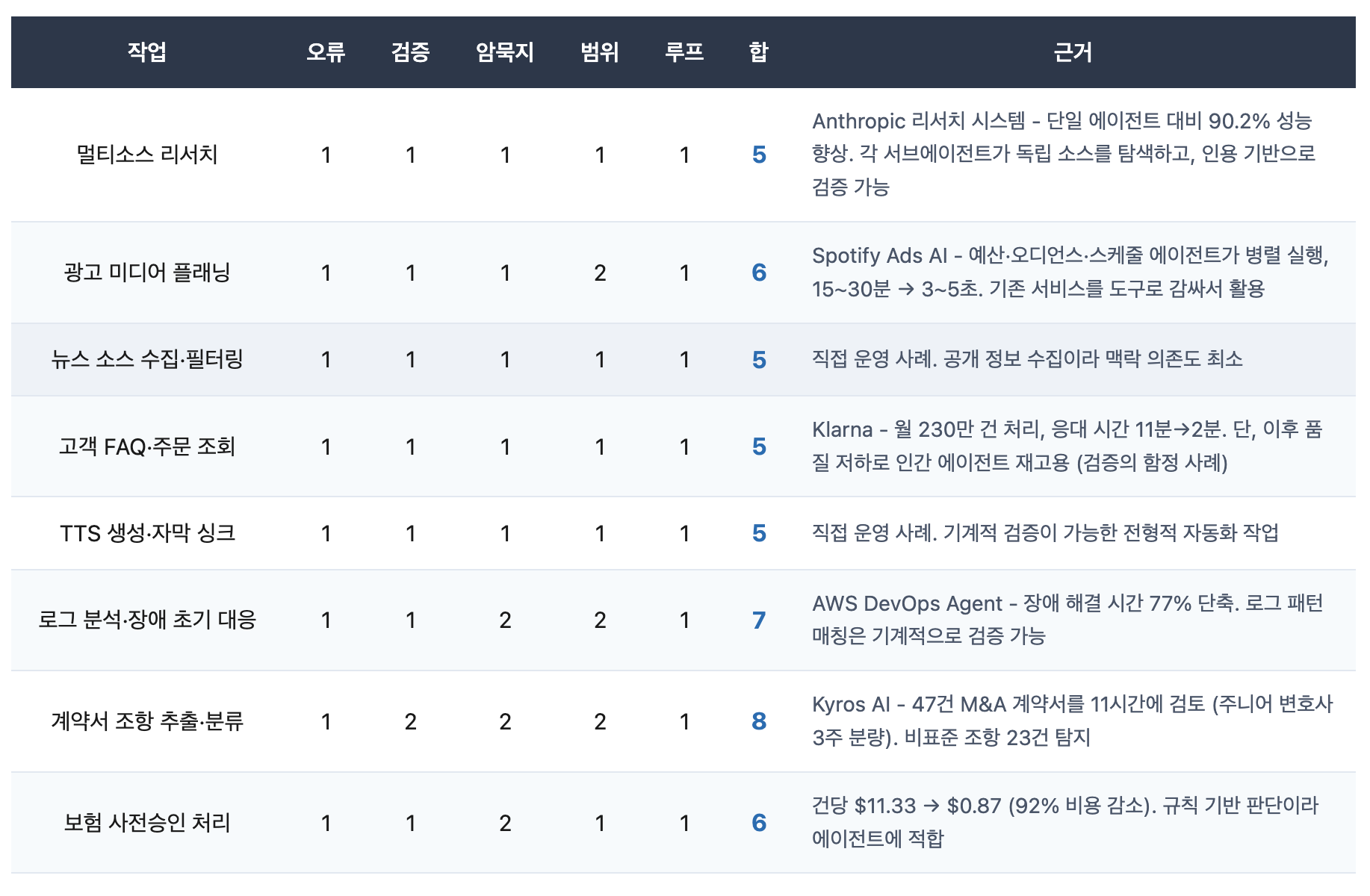
에이전트 주도가 자연스러운 영역 (5~10점)
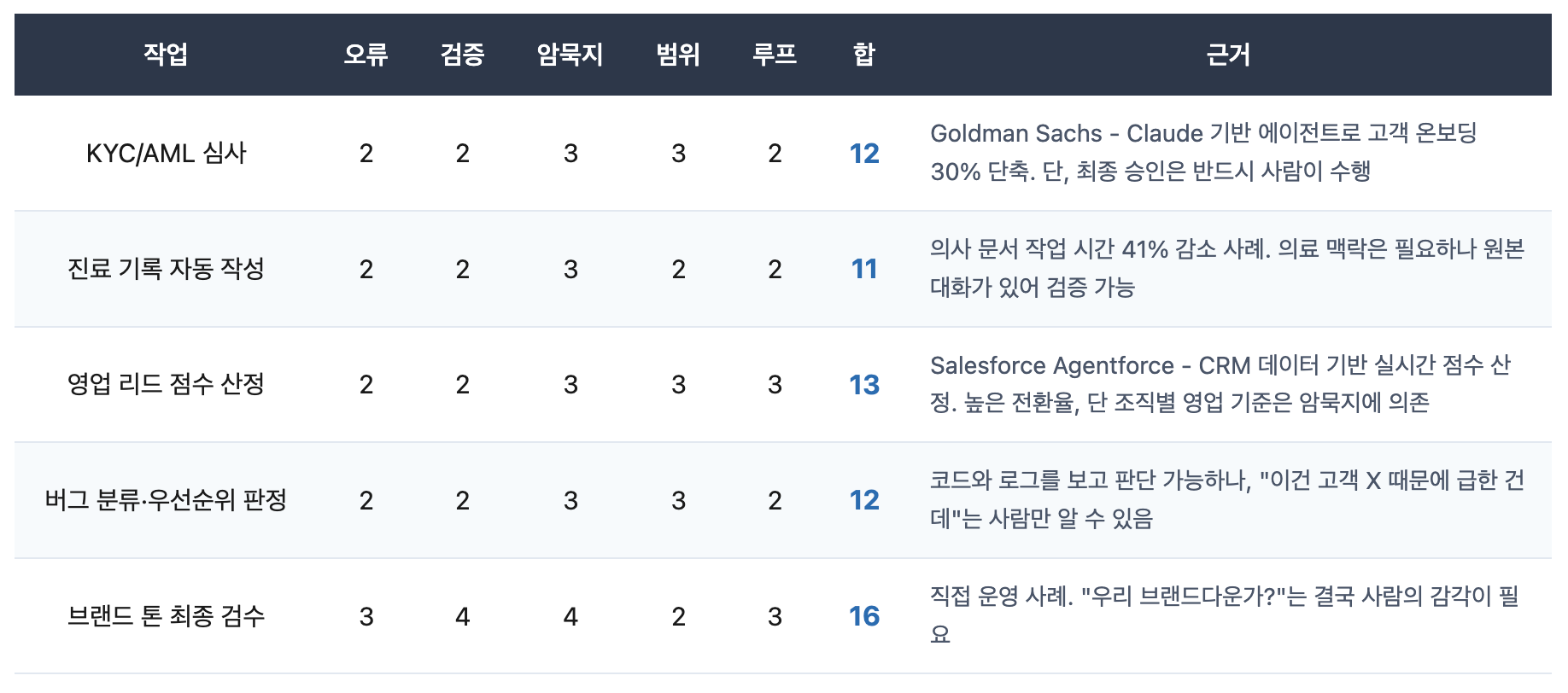
하이브리드 영역 (11~18점)
인간 주도가 필수인 영역 (19~25점)
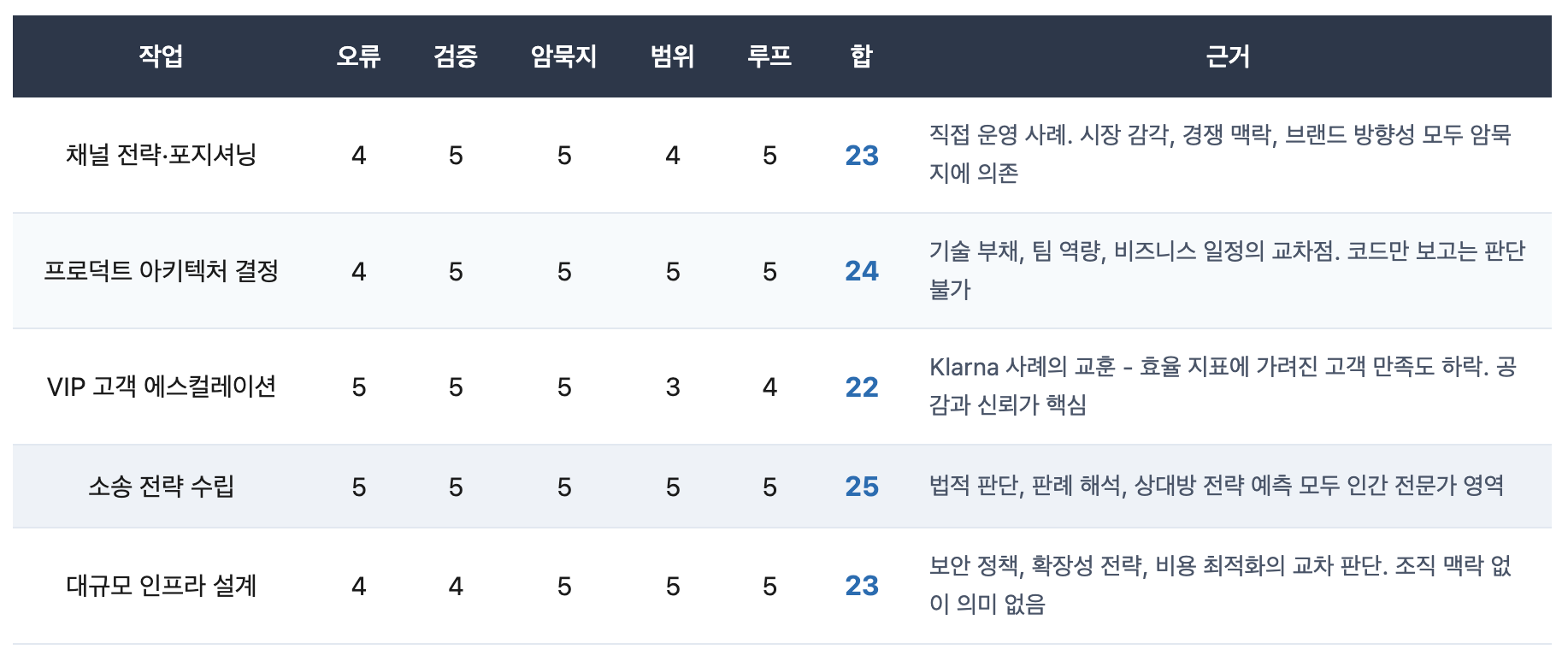
패턴이 보이시나요? 에이전트 주도 영역은 대부분 결과를 기계적으로 확인할 수 있고, 틀려도 되돌리기 쉬우며, 조직 맥락 없이도 작동하는 작업입니다. 반대로 인간 주도 영역은 결과의 옳고 그름을 단기간에 판단하기 어렵고, 실패 비용이 크며, 조직의 암묵지 없이는 의미 있는 판단이 불가능한 작업입니다.
오류 비용이 낮고 검증이 쉬운 영역부터 에이전트 주도가 자리잡고, 시간이 지나면서 전체적인 무게중심이 조금씩 이동하는 - 작업 단위의 점진적 확산이 현실적인 흐름입니다. 팀을 이끄는 입장에서 의미 있는 질문은 “에이전트를 도입할까 말까”가 아닌, 자기 팀의 업무 중 이러한 다섯가지 변수로 채점해보면서 낮은 부분을 찾아내는 것입니다.
마치며
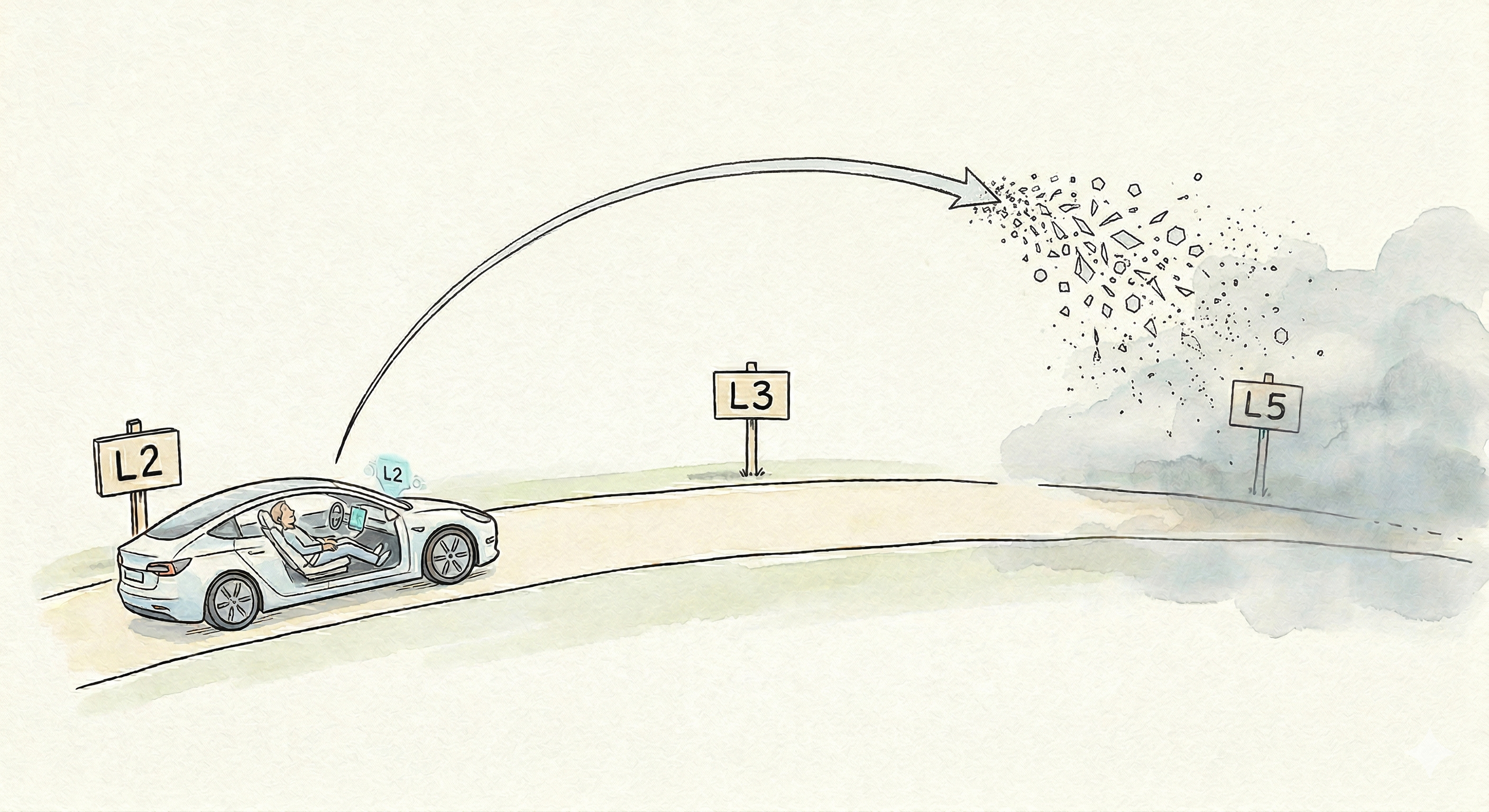
“에이전트 여러 개를 띄워서 회사처럼 돌리면 되지 않을까?” - 적어도 지금은, 안 됩니다.
자율주행에 비유하면, 지금 AI 에이전트는 L2(부분 자동화) 에서 L3(조건부 자동화) 로 넘어가려는 시점입니다. 그런데 Gastown이나 Paperclip은 L5(완전 자율주행) 를 바로 구현하려고 합니다. L2에서 L3도 쉽지 않은데 L5를 한번에 뛰어넘으려 했으니, 부딪히는 문제가 많을 수밖에 없었습니다.
때로는 모든 부분에서 혁신을 밀어붙이기보다 필요에 따라 “아직 타이밍이 되지 않았다”라는 판단을 내리는 것도 엔지니어링 의사결정입니다. 리서치처럼 낮은 점수가 나오는 도메인부터 에이전트에게 적극적으로 위임하고, 그렇지 않은 부분은 여전히 인간 중심 워크플로우 안에서 AI 에이전트를 자연스럽게 녹이는 시도를 해야합니다.
모든 도메인을 한번에 뒤집으려 하기보다, 각자의 영역에서 위임의 가치를 하나씩 증명해 나가는 것 - 그게 지금 우리가 할 수 있는 가장 현실적인 한 걸음입니다.
참고 자료
연구
Why Do Multi-Agent LLM Systems Fail? - UC Berkeley, MAST 데이터셋. 1,642개 실행 기록에서 14가지 실패 모드 분류
Towards a Science of Scaling Agent Systems - Google DeepMind & MIT. 멀티에이전트 조율 전략 실험
AgentOrchestra - GAIA 벤치마크 89.04% 달성
프로젝트 & 프레임워크
Gastown / Gas City SDK - Steve Yegge의 에이전트 오케스트레이션
Paperclip - “제로 휴먼 컴퍼니” 에이전트 프레임워크
ClawTeam - 리더-워커 기반 멀티에이전트 시스템
플랫폼 & 프로덕트
Anthropic - Building effective agents, 멀티에이전트 리서치 시스템, Claude Code Agent Teams
OpenAI - Agents SDK
LangChain - LangGraph Swarm, Exa 딥 리서치 에이전트
Spotify - 멀티에이전트 광고 아키텍처
Cursor - The Third Era
Linear - Introducing Linear Agent